In the last post in this short series, we looked at how to build a small neural network to solve the XOR problem. The network we built can generate an output for any of the inputs that we gave it from the table. It’s most likely that it sometimes gets the wrong answer, because the weights on the links were randomly generated.
Now we’ll look at getting the network to learn from it’s mistakes so that it gets better each time. In the context of neural networks, learning means adjusting those weights so it gets better and better at giving the right answers.
The first step is to find out how wrong the network is. This is called the cost or loss of the network. There are several ways to do this from the simple to the complex. A common approach is called “logistic regression”, which avoids problems of the neural network getting stuck in it’s learning.
Recall from our XOR table that there are two possible outputs, either 1 or 0. There will be two different versions of the cost depending on the output:

Remember that hθ(x) is the hypothesis that the network produces, given the input x=(x1,x2) and the weights θ. “log” is the standard mathematical function that calculates the natural logarithm of the value given (hence the name “logistic regression”).
We can combine these two instances together in a single formula that makes it easier and faster to translate into code:
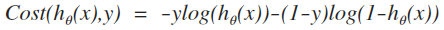
So our code to represent this:
y = 0; J = ((y * log(h)) + ((1 - y) * log(1 - h))) * -1 ;
This gives us a good idea how the network is performing on this particular input, with y set to the expected output from the first row of the XOR table.
A better network will have a lower cost, so our goal in training the network is to minimize the cost. The algorithm used to do that is called the back propagation algorithm (or backprop for short).
The first step is to evaluate the error at the output node (layer 3):
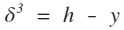
Note that the superscript 3 refers to the layer and doesn’t mean cubed! The code in Octave is:
delta3 = h - y;
So far, so straightforward. Backprop takes the error at a particular layer within a network and propagates it backward through the network. In general, the formula for that is:

This looks a little complicated so let’s dissect it to make it easier to understand and translate into Octave code.
Firstly, the l superscript on some of the terms in the formula refers to the layer in the network. The next layer we need to work out is layer 2, so l = 2. We already know what δ3 is from the previous code above.
Next, Θ(l-1) refers to the matrix of weights at the layer l-1. The T superscript means to transpose the matrix (basically swap the rows and columns). This makes it easier for us to multiple the two matrices. Octave being what it is makes this very easy for us, so the first part of the formula is easy to translate:
THETA2’ * delta3
Note the apostrophe after THETA2. This is Octave’s way of transposing a matrix.
The second part of the formula represents the derivative of the activation function. Fortunately, there is an easy way to calculate that without getting into the complexity of calculus:

The “.*” means element-wise multiplication of a matrix. So each term in the first matrix is multiplied by the corresponding term in the second matrix. In Octave, it’s almost exactly the same (for layer 2):
Z2 .* (1 - Z2)
Putting those two parts together then:
delta2 = ((THETA2' * delta3) .* (Z2 .* (1 – Z2)))(2:end);
Remember that these are matrix operations, so delta2 will be a matrix too. The last part of the line of code (2:end) means to take the second element of the matrix to the end. The reason this is done is because we are not propagating an error back from the bias node.
At this point, we have the error in the output at layer 3 and layer 2. Since layer 1 is the input layer, there isn’t any error there, so we don’t need to calculate anything.
The last step in the backprop is to adjust the weights now that we know those errors. This is also quite simple:

The formula says that the change to the weights Θ(l) is the activation values multiplied by the errors, adjusted by the value α, which represents the learning rate. The learning rate governs how large the adjustments to the weights are. It’s a bit of a misnomer in that it doesn’t relate to how “fast” the network learns, although that can be the effect of having a relatively larger value. For solving the XOR problem, a learning rate of 0.01 is sufficient.
So in Octave:
THETA2 = THETA2 - (0.01 * (delta3 * A2')); THETA1 = THETA1 - (0.01 * (delta2 * A1'));
Once we’ve adjusted the weights in the matrices, the network will give us a slightly different hypothesis for each of our inputs. We can recalculate the cost function above to see how much improvement there is.
If we repeat the calculations, the cost should start reducing and the network will get better and better at producing the desired output.

In the next post, we’ll pull all the code together and see what happens when we start training the network across all the examples.

Will not updating the weights simultaneously with temp variables alter the results in any significant way?
LikeLike
I honestly really like the tutorial, but i keep having error-messages at line
“delta2 = ((THETA2′ * delta3) .* (Z2 .* (1 – Z2)))(2:end)” about non-conforming matrix dimensions
i thought i fixed it by simply transposing the second matrix, but then ended up with a 1×5 matrix that caused more errors down the line.
LikeLiked by 1 person
continueing my previous comment.
it solved the matrix-dimensions problem by adding a 0 to the Z2 matrix (indicating that the net-input for the hidden biasnode is zero. that solved it!
Thanks for this tutorial!
LikeLike
It’s a typo. It should be A2 instead of Z2:
“delta2 = ((THETA2′ * delta3) .* (A2 .* (1 – A2)))(2:end)”
LikeLiked by 1 person