
Previously I’ve shown how to work out the derivative of the Softmax Function combined with the summation function, typical in artificial neural networks.
In this final part, we’ll look at how the weights in a Softmax layer change in respect to a Loss Function. The Loss Function is a measure of how “bad” the estimate from the network is. We’ll then be modifying the weights in the network in order to improve the “Loss”, i.e. make it less bad.
The Python code is based on the excellent article by Eli Bendersky which can be found here.
Cross Entropy Loss Function
There are different kinds Cross Entropy functions depending on what kind of classification that you want your network to estimate. In this example, we’re going to use the Categorical Cross Entropy. This function is typically used when the network is required to estimate which class something belongs to, when there are many classes. The output of the Softmax Function is a vector of probabilities, each element represents the network’s estimate that the input is in that class. For example:
[0.19091352 0.20353145 0.21698333 0.23132428 0.15724743]
The first element, 0.19091352, represents the network’s estimate that the input is in the first class, and so on.
Usually, the input is in one class, and we can represent the correct class for an input as a one-hot vector. In other words, the class vector is all zeros, except for a 1 in the index corresponding to the class.
[0 0 1 0 0]
In this example, the input is in class 3, represented by a 1 in the third element.
The multi-class Cross Entropy Function is defined as follows:
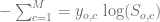
where M is the number of classes, y is the one-hot vector representing the correct classification c for the observation o (i.e. the input). S is the Softmax output for the class c for the observation o. Here is some code to calculate that (which continues from my previous posts on this topic):
def x_entropy(y, S):
return np.sum(-1 * y * np.log(S))
y = np.zeros(5)
y[2] = 1 # picking the third class for example purposes
xe = x_entropy(y, S)
print(xe)
1.5279347484961026
Cross Entropy Derivative
Just like the other derivatives we’ve looked at before, the Cross-Entropy derivative is a vector of partial derivatives with respect to it’s input:
![\frac{\Delta XE}{\Delta S} = \left[ \frac{\delta XE}{\delta S_{1}} \frac{\delta XE}{\delta S_{2}} \ldots \frac{\delta XE}{\delta S_{t}} \right]](https://s0.wp.com/latex.php?latex=%5Cfrac%7B%5CDelta+XE%7D%7B%5CDelta+S%7D+%3D+%5Cleft%5B++%5Cfrac%7B%5Cdelta+XE%7D%7B%5Cdelta+S_%7B1%7D%7D+%5Cfrac%7B%5Cdelta+XE%7D%7B%5Cdelta+S_%7B2%7D%7D+%5Cldots+%5Cfrac%7B%5Cdelta+XE%7D%7B%5Cdelta+S_%7Bt%7D%7D++%5Cright%5D+&bg=ffffff&fg=5e5e5e&s=0&c=20201002)
We can make this a little simpler by observing that since Y (i.e. the ground truth classification vector) is zeros, except for the target class, c, then the Cross Entropy derivative vector is also going to be zeros, except for the class c.
To see why this is the case, let’s examine the Cross Entropy function itself. We calculate it by summing up a product. Each product is the value from Y multiplied by the log of the corresponding value from S. Since all the elements in Y are actually 0 (except for the target class, c), then the corresponding derivative will also be 0. No matter how much we change the values in S, the result will still be 0.
Therefore:
![\frac{\Delta XE}{\Delta S} = \left[ \ldots \frac{\delta XE}{\delta S_{t}} \ldots \right]](https://s0.wp.com/latex.php?latex=%5Cfrac%7B%5CDelta+XE%7D%7B%5CDelta+S%7D+%3D+%5Cleft%5B+%5Cldots+%5Cfrac%7B%5Cdelta+XE%7D%7B%5Cdelta+S_%7Bt%7D%7D+%5Cldots+%5Cright%5D&bg=ffffff&fg=5e5e5e&s=0&c=20201002)
We can rewrite this a little, expanding out the XE function:
![\frac{\Delta XE}{\Delta S} = \left[ \ldots \frac{\delta -(Y_{c}\textup{log}(S_{c}))}{\delta S_{c}} \ldots \right]](https://s0.wp.com/latex.php?latex=%5Cfrac%7B%5CDelta+XE%7D%7B%5CDelta+S%7D+%3D+%5Cleft%5B+%5Cldots+%5Cfrac%7B%5Cdelta+-%28Y_%7Bc%7D%5Ctextup%7Blog%7D%28S_%7Bc%7D%29%29%7D%7B%5Cdelta+S_%7Bc%7D%7D+%5Cldots+%5Cright%5D&bg=ffffff&fg=5e5e5e&s=0&c=20201002)
We already know that 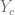
![\frac{\Delta XE}{\Delta S} = \left[ \ldots \frac{\delta -\textup{log}(S_{c})}{\delta S_{c}} \ldots \right]](https://s0.wp.com/latex.php?latex=%5Cfrac%7B%5CDelta+XE%7D%7B%5CDelta+S%7D+%3D+%5Cleft%5B+%5Cldots+%5Cfrac%7B%5Cdelta+-%5Ctextup%7Blog%7D%28S_%7Bc%7D%29%7D%7B%5Cdelta+S_%7Bc%7D%7D+%5Cldots+%5Cright%5D&bg=ffffff&fg=5e5e5e&s=0&c=20201002)
So we are just looking for the derivative of the log of 
![\frac{\Delta XE}{\Delta S} = \left[ \ldots -\frac{1}{S_{c}} \ldots \right]](https://s0.wp.com/latex.php?latex=%5Cfrac%7B%5CDelta+XE%7D%7B%5CDelta+S%7D+%3D+%5Cleft%5B+%5Cldots+-%5Cfrac%7B1%7D%7BS_%7Bc%7D%7D+%5Cldots+%5Cright%5D&bg=ffffff&fg=5e5e5e&s=0&c=20201002)
The rest of the elements in the vector will be 0. Here is the code that works that out:
def xe_dir(y, S):
return (-1 / S) * y
DXE = xe_dir(y, S)
print(DXE)
[-0. -0. -4.60864 -0. -0. ]
Bringing it all together
When we have a neural network layer, we want to change the weights in order to make the loss as small as possible. So we are trying to calculate:
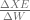
for each of the input instances X. Since XE is a function that depends on the Softmax function, which itself depends on the summation function in the neurons, we can use the calculus chain rule as follows:
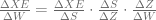
In this post, we’ve calculated 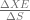

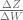
print(np.dot(DXE, DL_shortcut).reshape(W.shape))
[[ 0.01909135 0.09545676 0.07636541 0.02035314 0.10176572]
[ 0.08141258 -0.07830167 -0.39150833 -0.31320667 0.02313243]
[ 0.11566214 0.09252971 0.01572474 0.07862371 0.06289897]]
Shortcut
Now that we’ve seen how to calculate the individual parts of the derivative, we can now look to see if there is a shortcut that avoids all that matrix multiplication, especially since there are lots of zeros in the elements.
Previously, we had established that the elements in the matrix 
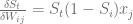
where the input and output indices are the same, and

where they are different.
Using this result, we can see that an element in the derivative of the Cross Entropy function XE, with respect to the weights W is (swapping c for t):

We’ve shown above that the derivative of XE with respect to S is just 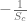

This simplifies to:

Similarly, where i <> c:
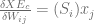
Here is the corresponding Python code for that:
def xe_dir_shortcut(W, S, x, y):
dir_matrix = np.zeros((W.shape[0] * W.shape[1]))
for i in range(0, W.shape[1]):
for j in range(0, W.shape[0]):
dir_matrix[(i*W.shape[0]) + j] = (S[i] - y[i]) * x[j]
return dir_matrix
delta_w = xe_dir_shortcut(W, h, x, y)
Let’s verify that this gives us the same results as the longer matrix multiplication above:
print(delta_w.reshape(W.shape))
[[ 0.01909135 0.09545676 0.07636541 0.02035314 0.10176572]
[ 0.08141258 -0.07830167 -0.39150833 -0.31320667 0.02313243]
[ 0.11566214 0.09252971 0.01572474 0.07862371 0.06289897]]
Now we have a simple function that will calculate the changes to the weights for a seemingly complicated single-layer of a neural network.
